Identity Governance and Administration (IGA) has a long and often tortured history. Emerging 20+ years ago in response to financial services regulation such as 2002 Sarbanes-Oxley Act or the 1999 Gramm-Leach-Bliley Act it was often littered with complex project analysis phases, tooling that had limited integration capabilities and user experiences that were far from perfect.
The result was a litany of IGA projects there left incomplete, managed by manual fulfilment processes and requiring costly change and upgrade improvements.
However, in 2024 things are much different. The IGA problem statement has become larger – with more systems requiring data cleanup and access request management, more identities need managing, more identity types exist and a complex myriad of hybrid deployment patterns exist, all vying for a position under an IGA umbrella.
How can existing and new IGA projects handle such broad and subtly complex requirements? By focusing on the identity data layer would likely be a good start. In a recent piece of commissioned content I wrote for identity automation provider Readibots, I took a look at the need to understand the data automation function within the identity data life cycle.
The main failings of existing IGA projects can be summarised quite commonly by having characteristics similar to the following:
- Limited application coverage
- High-effort process redesign
- High professional services-lead implementation costs
- High percentage of manual error-prone processes
- An inability to adapt to new business requirements
Spending effort tactically on additional connectors or attempting to redesign existing business-focused processes can lead to increasing costs and continual technology swap-outs.
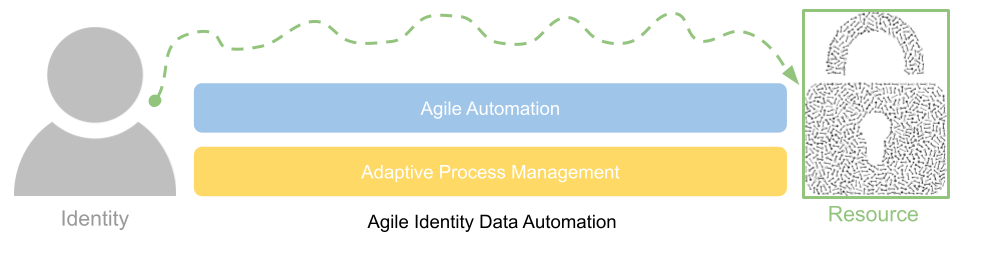
The abstraction of the existing IGA tooling coupled with a more agile approach to connectivity, data management and process alignment can accelerate and streamline existing manual processes and system connectivity issues.
Essentially, more systems need to be managed by existing IGA capabilities – but in a way that does not require extensive process redesign. It is important to overlay existing data sources and manual fulfilment processes with automation – essentially taking what works, and accelerating the effectiveness – by removing human intervention or error prone steps.
The benefits of a more flexible and connected identity data fabric include measurable benefits:
- Reduction in access request and fulfillment time with broad application coverage
- Adaptable automation results in less processing errors
- Closer alignment to business outcomes and change
- Automation leads to improved security assurance and compliance
- Identity data is cleaned in a sustainable manner
Take a read of the original article to learn more.