
| Last Updated | 11 January 2022 |
| Document Tag | tch-research-next-gen-authz |
| Author | simonm@thecyberhut.com |
| Part of Research Product | Next Generation Authorization Technology |
Summary

The What? A Declarative access control language and lightweight decision agent
The Why? Policy-based control for cloud native environments – Flexible, fine-grained control for administrators across the stack
The Where? https://www.openpolicyagent.org/

Introduction
Open Policy Agent (OPA) is focused on creating a broad coverage lightweight approach to access control policy design and decisioning. It comes with a language designed explicitly for creating fine grained access control rules. The website also mentions the use of context – additional information that can be leveraged during the access enforcement process.
The enforcement deployment aspect is very much focused on the microservices and Kubernetes (K8) ecosystem – where the use of everything “as code” extends very much to the access control infrastructure.
OPA can be deployed as both a daemon (that is as a separate process) and as an embedded service via a Go library. The policy authoring aspect is done via integrated developer environment plugins and the OPA playground – which is a web based training and testing area. The main strap they use is “policy as code”. OPA is described as a generic policy engine, allowing it to protect a range of emerging targets – such as APIs and HTTP services.
Architecture
OPA is created to decouple the decision making aspect from the access control enforcement aspect. Here the OPA receives queries and in return provides guidance back to the calling service in order to enforce access.
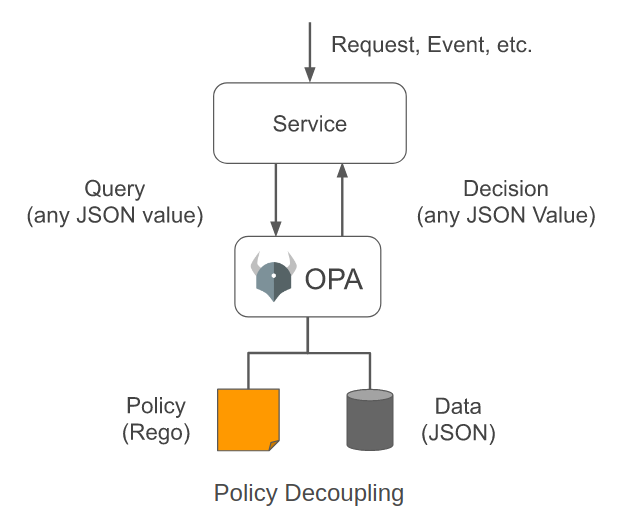
OPA will receive a generic JSON payload as input, then via the use of locally defined policies and static data, make a decision – which in turn is sent back to the caller.
The generic nature of the agent, allows a range of things to be protected – from infrastructure configuration and access to the more fine grained subject-object-action style decisions.
OPA policies are designed using a language called Rego. The policies work on an “input” object which policies can then leverage operators and evaluators against to come to conclusions.
Re-use of conditions comes in the form of “rules” which allow greater expansion and complexity. The rule has a “head” which returns true/false based on information within the “body”. This example is taken from their documentation.
any_public_networks = true { # is true if...
net := input.networks[_] # some network exists and..
net.public # it is public.
}In the above example, the value true occurs if the network is public or the value set within input.networks (aka the inbound payload) is set.
The documentation describes a simple way to download the OPA executable, then run the exe with an input file and a data file – aka the file that contains the rules logic.

In this case, the OPA exe is run against an input file of static data, a rules file called example.rego and some runtime data.
The OPA exe also has a REPL (read-eval-print-loop) mode which can be accessed by entering the “run” argument. This allows immediate evaluation on the command line.
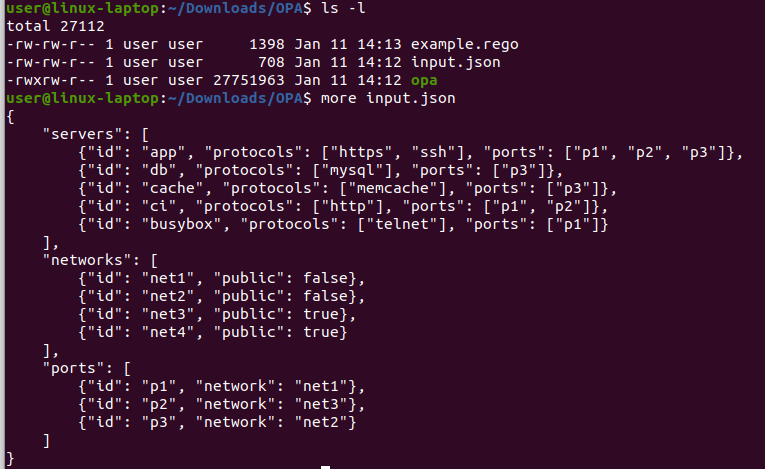
So here I created a simple input.json which I copied from the OPA docs site along with the example.rego rules file.
I can now run the following and experiment at runtime with data evaluation.
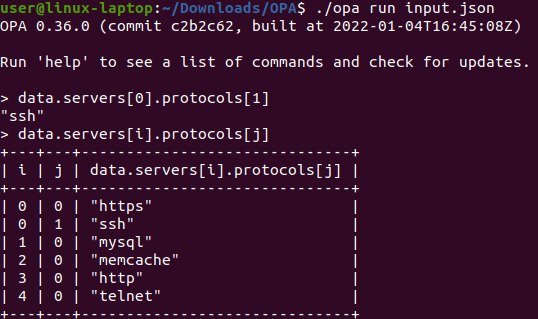
So here I’m just running OPA against the input.json and iterating over the payload and seeing what the responses are – for example: data.servers[0].protocols[1] (the numbers are just the array position) will return “ssh” as per the input.json file above.
The next interesting stage, is to run the OPA exe in server mode – so it can respond to requests over HTTP.

The above starts the server on the default port of 8181. I can now send queries in JSON to the engine and based on the example.rego rules file it is running, get a decision response back.
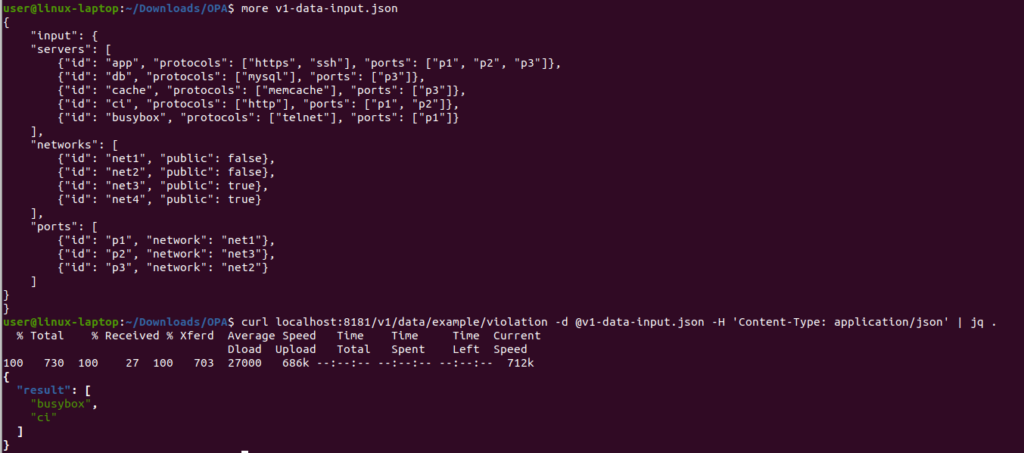
Here I have a data input file (v1-data-input.json) which is just a copy of the original input.json from the OPA site. I send this across to the 8181 port and the OPA server evaluates and returns a JSON decision back.
If the executable isn’t enough fun, the OPA components can be embedded directly into your application via a Go library. Go was likely chosen as the main K8 ecosystem is Go friendly.
Policies
The OPA site has a section that describes it’s “philosophy” – essentially that authorization can be decoupled from the downstream protected system and codified into policy documents, which the OPA service can interpret. The docs make an interesting comment regarding the difference between authentication and authorization (clearly many confuse the two) and also how authorization may not always be focused upon an identity – for example the policy maybe entirely service or infrastructure related with respect to it’s purpose.
They make a good point regarding decoupling – that policies can have a different cadence with respect to versioning and updates to that of the target system that is being protected.
The policies are authored in a language called Rego – which the OPA site says focuses upon how the policy will return result, rather than how it will evaluate the query.
Policies can be tested by the creation of separate test files, that are also written in Rego. The test file will contain a set of conditions along with data to trigger those conditions – for example the allowing or denying or particular events. This allows data inputs to be selected to trigger certain scenarios.
The main deployment scenario for OPA is that of microservices. As such, high throughput and low latency are of huge concern and the OPA site states that most microservices environments have a budget of around 1 millisecond when it comes to evaluation response. One of the features that OPA has with respect to speed, is that of “linear fragment” which refers to the process of reading and processing the policy data just once in order to come to a conclusion. The idea being that there is no querying and searching for a result. Another aspect OPA promotes, is the use of objects over arrays, allowing policies to search and in turn evaluate more quickly.
Policies can also be created with the ability to “early exit” once a condition has been met, negating the need for further processing.
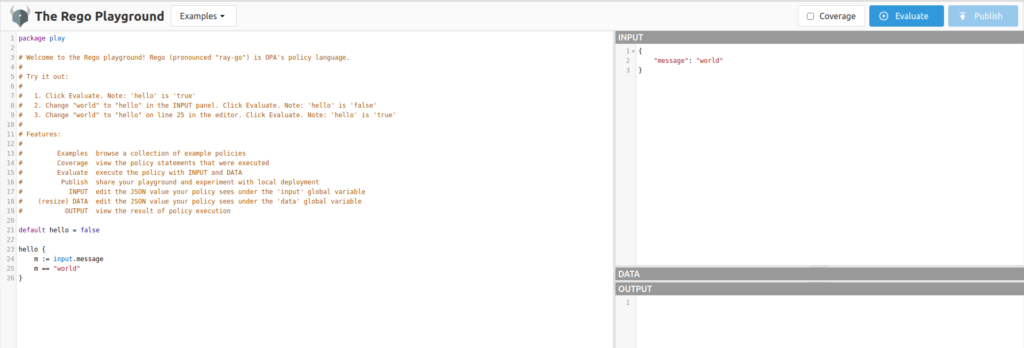
Rego Playground
Rego may well be new to a lot of application developers or identity architects for that matter, so there is a Rego “playground” that provides some good learning and testing features.
Contextual Processing
OPA policies can leverage external data sources before making a decision. OPA isn’t the true source of this data but it can be used all the same. An example includes identity data (in the form of the omnipresent JWT (“jot token”).
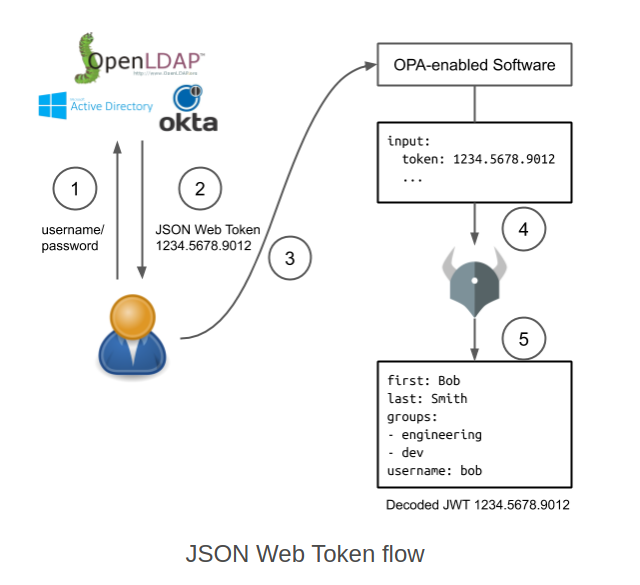
This is again amplifying the design pattern of decoupling the authentication and authorization processes from each other, which increases the number of moving parts, but allows more flexibility and management. A limitation in the sense of identity data coming in the form of tokens, is that the data is only as fresh as the latest authentication event – which will essentially last for as long as the token is valid and has an exp (expiry) time that is still valid.
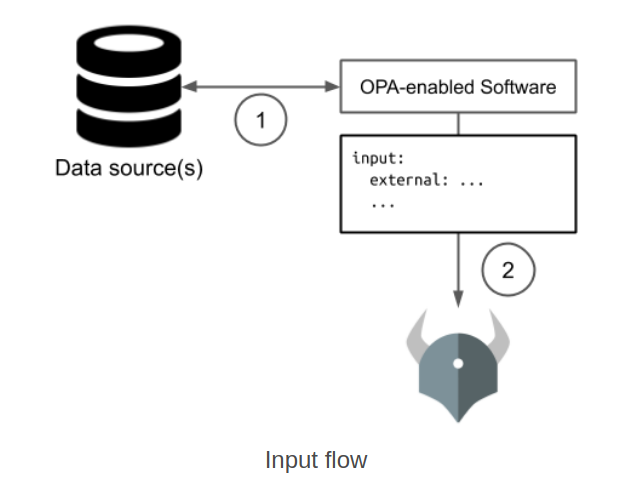
A similar pattern applies to more generic data sources, which can be pulled in at runtime and in turn presented to the OPA engine for evaluation. This model focuses on the calling system retrieving the necessary meta data before passing into the OPA engine.
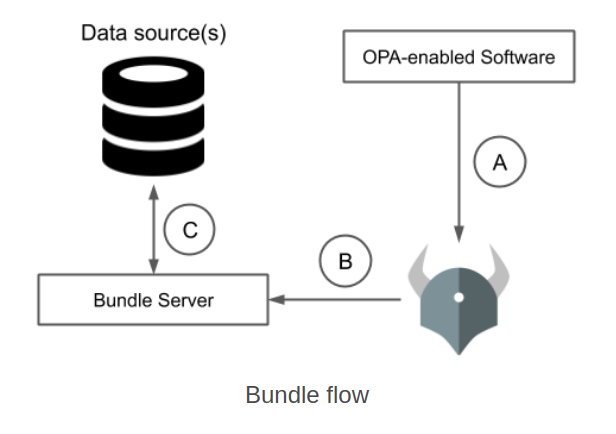
A third design pattern refers to “bundling”. Here data as well as policy can be pulled down to the OPA instance – with the assumption the data aspect doesn’t change that frequently.
Additional data can also be “pushed” and “pulled” down to the OPA engine instance. Clearly both models will have design considerations, especially with respect to network access, bandwidth requirements and latency.
Integration
The OPA site discusses two integration areas to consider – the run time evaluation of policy and the management of the authorization infrastructure.
From an eval perspective there are a few options – namely a REST API using OPA as an HTTP service, embedded capabilities by leveraging the Go library and also a higher level SDK.
The REST API will expect JSON payloads to be sent to it that contain the data to be evaluated. The request path can also contain the policy decision to ask for. For example the OPA docs list the following as an example path to request for evaluating if the user in the input payload is an admin:
example/authz/is_adminA more generic one for evaluating an evaluating request may use:
example/authz/allowAn input payload JSON example to the authz/allow endpoint could look like:
POST /v1/data/example/authz/allow
Content-Type: application/json
{
"input": {
"method": "GET",
"path": ["salary", "bob"],
"subject": {
"user": "bob"
}
}
}REST API
The REST API isn’t just for policy evaluation. It can also be used for management. There is a policies endpoint with full CRUD (create-read-update-delete) capabilities with policy data encapsulated within a JSON payload.
In addition to policies, data can also be sent down to an OPA instance. This data is eval’d at runtime alongside the policy and input data.
A feature worth mentioning is how authentication is handled on this API. There is a flag (–authentication=token) that requires the use of a bearer token as part of the HTTP authorization header that is sent with each API request.
Configuration
The OPA instance can be started with a configuration file that handles the deployment detail. This config file can be JSON or YAML based.
Some interesting configuration options include the bearer token authentication, client TLS detail, OAuth2 client credentials detail and the discovery service for identifying bundle download locations.
The OPA site has a specific section on security – where the assumption is the deployment will occur within an untrusted environment – I wonder if that should really be the standard deployment assumption anyway? The configuration is focused upon TLS. Another assumption is that the evaluation API be only available via “localhost” – in order to prevent remote access by adversaries. However, if only local services can access, issues such as health monitoring and metrics can’t be access remotely. OPA have thought of that and separate listeners are available.
Some additional hardening steps are also listed including running under a non-root user and not to pass credentials as command line arguments (I’m guessing as they can be logged by intermediary processes).
Ecosystem
The generic approach to access control, has clearly lead to OPA being integrated into a range of different systems. As as result, there is an ecosystem area that contains a range of prebuilt integrations.

Many of the integrations focus on the microservices infrastructure space with some components for envoy, Kubernetes and the like. There are also gateway integrations for the like of Kong and language specific integrations for Java and PHP.
The icons vector off to github repo’s, so support will likely come from the community.
All images from the OPA website unless specified.