
| Last Updated | 01 June 2022 |
| Document Tag | tch-research-next-gen-authz |
| Author | simonm@thecyberhut.com |
| Part of Research Product | Next Generation Authorization Technology |
What is driving the demand for new authorization models, software vendors and emerging authorization design patterns?
Previous Failures
RBAC
Role Based Access Control has been the mainstay for enterprise authorization control for at least two decades. Many implementation approaches, software vendors and maturity models where developed to assist with the design of business roles, applications roles and user to role association rules.
Many emerging declarative authorization approaches leverage roles as a means to associate users to the more fine grained permissions models of the protected sub-systems.
However, RBAC has been troubled by many implementation issues.
Costly Business Analysis
Before roles can be created for an organisation or department, a thorough and at times complex analysis of the business functions, outcomes and processes needs to take place in order to understand how the initial role model should be created. This “top down” analysis will involve interviews, systems analysis and personnel structures including things like office locations, cost centres, job grades, department codes and so on. This in turn helps to create business or function roles that users can be associated with. This analysis phase is typically done by an external specialist consultancy that has the necessary experience. By association this phase can take several months.
Complex System Analysis
Top down business roles, in turn need to be associated with down stream systems via permissions collections – often handled via technical roles or application roles. This phase requires detailed technical understanding of the protected sub-system such as RACF mainframe, SQL databases or custom application permissions. Those permissions are then grouped according to similarities identified within the associated functional or business roles. This system analysis phase will be done by a combination of external consultants and in-house application specialists, who understand the nuance associated with custom systems or the specific implementation detail of commercial of the shelf products.
Role Explosion
After the initial top down and bottom up system analysis, the early versions of the role model are identified. However, many role implementations often lack the necessary governance and long term operational support models. The result can see a rapid increase in the creation of new roles for functional groups, users with exceptional permissions associations and new system level capabilities. The outcome is a system where the number of roles starts to compare to the number of users within an environment. The typical “role explosion”. The operational management of this becomes cumbersome resulting in:
- Difficulties in searching for roles
- Knowing what each role does
- Difficulty in associating new users to their role model
- Difficult in reviewing associated access provisions
All of which increases the need for more roles in order to manage user relationships, with a perpetual “resetting” of the model – without the removal of existing roles and user associations.
The model essentially becomes too large to be useful.
XACML
Whilst XACML – the XML language for describing complex authorization – is not in itself a failure, it has likely given way to more lightweight and modular approaches to describing authorization logic as well as the implementation detail. The fact that XACML was based on XML could indicate that XACML is a language of the early 2000s, where complex Java based middle-ware was the mainstay of enterprise identity and access management.
We are now in the realm of agility where lightweight programming languages such as Go and node.js and an API first approach to service development that is based on REST and JSON are the main focus. A different technology stack certainly, but many of the principles of XACML may still hold true – such as the modular approach to policy design, decisioning and enforcement and the subject-object-action model of rule creation. However the number of new authorization projects leveraging XML and XACML may well be on the decline.
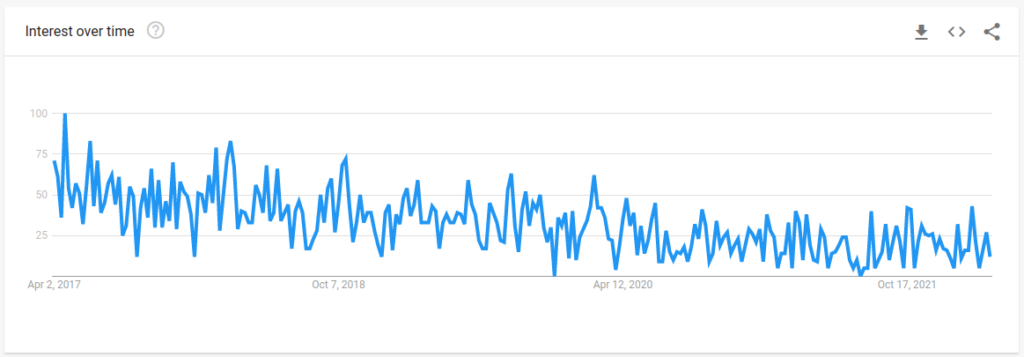
Source: Google Trends
A 5 year world wide search on Google Trends for the XACML programming language sees a general decline – with the peak search point being April 2017.
Identity Centric Security
The last 5-7 years has seen identity become a more foundational component in the modern security architecture landscape as well as being a key component in B2C external facing integrations that have powered many organisations increase their digital reach.
Zero Trust
The zero trust bandwagon has gained significant momentum since Google released their “BeyondCorp” whitepaper outlining their approach to managing distributed employee access to core Google services. This of course was after the emerging concepts of perimeter-less security came about from the likes of the Jericho Forum (with their Commandments) and the Forrester analyst at the time John Kingervag, often seen as the “inventor of zero trust”.
The concept is to essentially migrate trust from the assumed location of the device initiating the access request, to something more fine grained based on the context – of both the device and the location – irregardless of the perceived location.
The Google approach focuses on the use of a context aware proxy that is essentially intercepting object access requests and leveraging identity, device and request information in order to come to an access decision.
This basic model places greater emphasis on a decoupled identity authentication, device analysis and down stream access control security mechanisms.
The assumptions we can derive from the many zero trust approaches include:
- A movement to fine grained access control
- The ability to leverage device context during access control decision making
- The assumption that all controlled resources are accessible from uncontrolled networks
- A need for more frequent identity verification
- Access control that is based upon least privilege and dynamic permission association
- The number of objects requiring access control decisions increases
Contextual & Adaptive Access
A practical implementation of zero trust IAM, needs to focus upon two subtle concepts: context and adaptivity.
Context typically refers to the non-identity data used during a protocol run. That protocol run could be authentication or authorization related. The non-identity data really refers to internal and external data signals that can help evaluate the request. This could include (but is not limited to and will certainly evolve beyond) data signals such as:
- Device characteristics – model, OS version, browser version, application assurance
- Device location – geo coordinates, IP address, ISP details
- Identity profile data – last login date, last password change date, risk ratings, profile completeness, profile data freshness
- Threat intelligence data – breached credentials, network threat, application threat, CVE ratings
- Transaction data – behavior, history, comparison to peers
Capturing of the context will occur at both the authentication and authorization initial event, before allowing a mechanism to store, re-capture, compare and verify future context payloads.
Differences in contextual verification will likely lead to changes in the access control responsiveness. This is known as adaptive access. Here, a combination of policy decision point and enforcement point actions will work together to deliver a dynamic response to suspected changes in the captured context.
A change in the device characteristics mid-session for example may indicate a man-in-the-middle style attack is taking place – in which case a decronian response such as a standard access deny process should be initiated. However contextual differences are likely to become more subtle – perhaps threat intelligence intra-session may indicate that a previously secure credentially has become breached, or perhaps a mobile application has a new common vulnerability and exposure associated with it – that at time-1 was deemed to be at an acceptable risk level, but at time-2 has since moved to a risk level that requires response. The response here may well also be more subtle than a simple full denial. In environments where usability is key (for example B2C consumer identity), the response may well be focused upon access degradation, be temporal and recoverable.
For example, egress filtering on a reference monitor (think interception gateway) may redact or remove particular fields in a JSON payload if the identification of a contextual difference is found, that doesn’t warrant a full access denial.
Whilst the policies that drive such adaptive responses are relatively static, the data involved in evaluating the access control decision are highly volatile and dynamic.
Modern Enterprise Mesh
In extending what the modern application needs, we should also consider the needs in general of the modern enterprise.
Hybrid Cloud
The last three years has seen a significant shift in cloud computing demand – be it in the form of PasS, SaaS and IaaS.
A large (7500+ employee) enterprise is likely to have an array of different sources when it comes to application and service delivery. Some applications will of course always be controlled by the host enterprise and delivered “on-premises” – perhaps not in a traditional data centre, but via cloud-native devops processes using private cloud infrastructure – but alas, not publicly accessible.
In addition both official and shadow SaaS applications will be being leveraged to supply a range of functionality.
How does an organisation handle access control across a broad range of applications, that are not all controlled, have different APIs and service interfaces, leverage different identity sources and different access control models?
A process of centralised control may be needed – to create policy and support distributed identity visibility – as well as a way of applying distributed enforcement. How can access control be enforced against a web application on-premises as well as a cloud data lake that is controlled by a third party?
API and Microservices
Service functionality may also not be delivered by standalone applications and user interfaces. The “API-economy” provides a rich tapestry of singular functions – some built in house, some third party – that can be integrated to deliver more complex supply chains and ultimately business value. These APIs require both authentication and authorization functionality – both the north/source coarse grained level as well as the east/west fine grained level. Tokens are the popular choice here – with identity and authorization data often encapsulated in JSON Web Tokens – before being passed between individual services.
An entire new set of problems arise here – typically focused on token issuance, token exchange, throughput, scale and transaction volume. Standards such as OAuth2 are common and token exchange services are becoming increasingly popular to both issue and reissue tokens with specific fine grained scope sets and permissions.
Identity proliferation decisions also need to be made – in essence working out how far down the service supply chain the initial user identity should go.
Machine to Machine and Service to Service
An extension of the identity proliferation question, also creates secondary issues – around how service to service and machine and machine communications should be authenticated and authorized. Clearly non-person-entity security differs hugely from people based and the ability to make authorization decisions between different services becomes a new challenge. Tokens could be used, as well as more cryptographic based approaches to authentication, with secondary tokens being issued for more session specific authorization claims.
The same throughput and revocation questions get asked with respect to services authorization too.
Data Security
APIs are typically highly focused and deliver JSON payloads to both secondary services and direct to the end user’s calling application.
The content of that payload is the significant component – namely highly specific and focused data. Data drives business value, is the target for cyber criminals and contains a wealth of intellectual property. How can data be protected in a way that amplifies business agility and competitive advantage, whilst also having to contend with being located in a hybrid cloud environment, accessed by both people and non-person-entities such as services and machines?
The protection of data as close to its origin as possible is a common design pattern, with both ingress and egress filtering at both the SQL/noSQL data source as well as at the API service layer that is generating the data request.
Data protection at both the table and attribute level is common with concepts such as dynamic redaction, privacy enhancement via vaulting and encryption and tokenization services to help reduce the spread of PII and highly sensitive business data.
IoT
One final driver of authorization demand coming from changes to the modern enterprise landscape is that of IoT.
IoT device security is often misplaced, with the focus more on the data being collected, generated or forwarded to cloud data lakes. However, the IoT problem amplifies the need for data security – primarily how that data can be shared with third parties – who may be trusted, untrusted, known and unknown. The IoT proliferation “problem” becomes a data proliferation “problem” with nuisances around data sharing, revocation and privacy enhancement, all with the premise of constrained device origins and cloud aggregation.